- 4.9/5.0
- 106 Questions
- Updated on: 3-Aug-2026
- Enterprise Routing and Switching Specialist (JNCIS-ENT)
- 1106+ Prepared
- Valid Worldwide
Free JN0-351 Practice Test Questions | Know You're Ready for Enterprise Routing and Switching Specialist (JNCIS-ENT)
Exhibit:

When trying to commit the configuration shown in the exhibit, you receive an error.
What is the problem?
A. You have omitted the interface-mode trunk command.
B. You have not configured an IP address to the interface.
C. You have not set the interface family correctly.
D. You have omitted the interface-mode access command.
Explanation:
The error message states: "Access interface can be part of only one vlan". This indicates that the switch is treating ge-0/0/12 as an access port by default. Access ports allow membership in only a single VLAN.
However, the configuration attempts to assign the interface to two VLANs (v10 and v20) using the members [ v10 v20 ]; statement. This is only possible on a trunk port, which can carry multiple VLANs (tagged).
Because the interface-mode trunk command is missing, the switch defaults to access mode, causing the commit to fail. Adding interface-mode trunk; under the vlan hierarchy resolves the issue.
Why other options are wrong
B. You have not configured an IP address to the interface.
Incorrect. This is a Layer 2 switching interface (family ethernet-switching). IP addresses are not required or typically configured on such interfaces. Layer 3 functions are handled by VLAN interfaces (IRB/vlan unit), not physical access/trunk ports.
C. You have not set the interface family correctly.
Incorrect. The family ethernet-switching is correct for a switch port. Changing the family to inet would convert it to a Layer 3 interface, which would not solve the multi‑VLAN membership issue.
D. You have omitted the interface-mode access command.
Incorrect. Access mode is the default; omitting interface-mode access does not cause an error because it is implicit. Adding interface-mode access explicitly would still not allow multiple VLANs — the error would persist because access ports cannot have multiple VLAN members.
Reference
Juniper TechLibrary: “Configuring Trunk Ports” – “For trunk ports, include the interface-mode trunk statement. Trunk ports can carry multiple VLANs. Access ports (default) can belong to only one VLAN.”
JNCIS‑ENT Study Guide (Layer 2 Switching / VLANs) – “Access ports are assigned to a single VLAN. Trunk ports carry multiple VLANs using 802.1Q tagging. Omission of interface-mode trunk when multiple VLANs are listed causes a commit error.”
Exhibit.
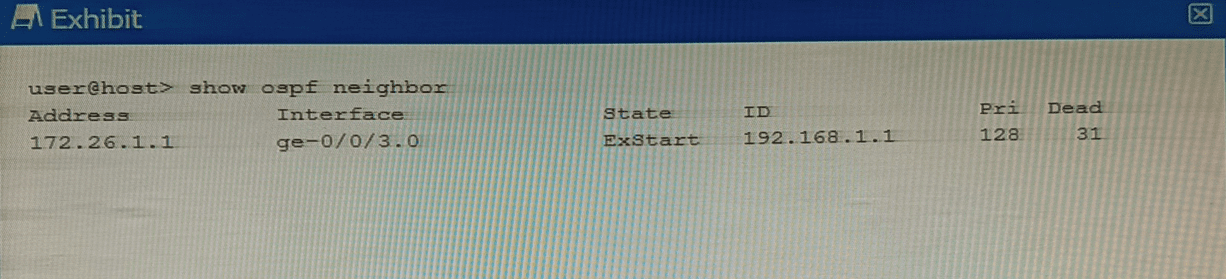
Why is this OSPF adjacency remaining in this state?
A. A subnet mask mismatch exists between the OSPF neighbors.
B. An MTU mismatch exists between the OSPF neighbors.
C. A hello interval mismatch exists between the OSPF neighbors.
D. An area ID mismatch exists between the OSPF neighbors
✅ Explanation:
The OSPF adjacency is stuck in the ExStart state. In the OSPF neighbor formation process, routers transition through several states: Down → Init → 2-Way → ExStart → Exchange → Loading → Full .
After establishing bidirectional communication (2-Way state), routers enter the ExStart state . During this phase, neighboring routers negotiate a master/slave relationship and determine the initial Database Descriptor (DBD) packet sequence number. The first DBD packet exchanged contains the interface MTU value in the packet header .
❌ Why Other Options Are Wrong
A. A subnet mask mismatch exists between the OSPF neighbors.
Incorrect. Subnet mask mismatches prevent OSPF from advancing beyond the Init or 2-Way state. Hello packets contain subnet mask information, and mismatches cause the adjacency to stall much earlier .
C. A hello interval mismatch exists between the OSPF neighbors.
Incorrect. Hello interval mismatches are detected when Hello packets are first exchanged. This prevents the adjacency from progressing beyond the Init state, not the ExStart state .
D. An area ID mismatch exists between the OSPF neighbors.
Incorrect. Area ID mismatches also cause failure in the Init state. Routers with mismatched area IDs never proceed to neighbor state beyond Init because Hello packets carry the area information, which is validated before any adjacency formation begins .
📚 Reference
Cisco Support Documentation: "Troubleshoot OSPF Neighbors Stuck in Exstart/Exchange State" – "The problem occurs when the maximum transmission unit (MTU) settings for neighboring router interfaces do not match"
ExamTopics JN0-363 Discussion – Community verified answer: "mismatched MTU settings on the OSPF interfaces" is correct
Click the Exhibit button.
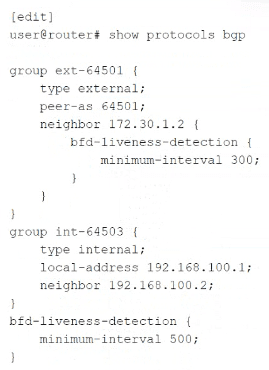
Which statement concerning Bidirectional Forwarding Detection (BFD) is true for the
configuration shown in the exhibit?
A. The effective interval for neighbor 172.30.1.2 is 500 ms.
B. The effective interval for neighbor 192.168.100.2 is 500 ms.
C. The link 1o neighbor 192.168.100.2 is not using BFD.
D. The minimum-interval must match on both ends.
Explanation:
BFD requires both endpoints to agree on detection timing. The configured minimum-interval value on one router must be compatible with the remote router's configuration. If the values are mismatched, the session may fail to establish or may flap. Even if negotiation occurs (using the larger of the two values), the fundamental requirement is that both ends must be configured in a compatible way. Statement D is a universal truth for BFD, independent of the specific numbers in the exhibit.
Why other options are wrong:
A. The effective interval for neighbor 172.30.1.2 is 500 ms.
Incorrect. Neighbor 172.30.1.2 has an explicit BFD configuration with minimum-interval 300 under the neighbor stanza. This overrides the global value (500 ms). The effective interval is 300 ms, not 500 ms.
B. The effective interval for neighbor 192.168.100.2 is 500 ms.
Incorrect in principle, though numerically it might appear true. Neighbor 192.168.100.2 has no explicit BFD configuration, and its group (int-64503) also has none, so it inherits the global value of 500 ms on the local router. However, the statement implies this is the effective interval for the session. BFD requires both ends to agree; without knowing the remote router's configuration, we cannot confirm the effective session interval. More importantly, many exam resources treat this statement as incorrect because the question focuses on BFD requirements, not just local inheritance. The guaranteed true statement is D.
C. The link to neighbor 192.168.100.2 is not using BFD.
Incorrect. Because the global BFD configuration applies to all BGP peers without their own BFD settings, neighbor 192.168.100.2 is using BFD with the global minimum-interval 500.
References:
Juniper TechLibrary: “BFD Minimum Interval” – “The minimum interval must be compatible on both sides of the BFD session.”
JNCIS‑ENT Study Guide (BFD) – “BFD configuration hierarchy: neighbor overrides group, group overrides global. Mismatched intervals across peers prevent session establishment.”
| Page 5 out of 14 Pages |